Getting to Know Dplyr
Guest Post by Keith Lewis
I’d first like thank Chris for letting me guest blog. This is an idea I’ve been toying with for some time but the lack of technical web skills has always held me back.
Advanced data manipulation in R with plyr/dplyr
A Brief Overview
The plyr/dplyr packages are primarily meant for ‘data wrangling’ or manipulation of data sets. I believe they are the most useful of Hadley Wickham’s many contributions to R and I find myself continually using them, especially the newer dplyr package. Like ggplot2, the application of this package is really limited only by your creativity.
Briefly, the idea behind these packages is that we often need to split a data set, do something to it (apply), and then combine it back together again. So the primary purpose is data manipulation.
Like many of Wickham’s packages, there has been an evolution. Plyr is the older version of the package and was meant to replace the many ‘apply’ functions available in base R. Plyr would use the split-apply-combine strategy to summarize (e.g. take a mean and SD for the levels of a categorical variable) or transform, i.e. create a new variable. Dplyr was introduced in 2014 and has far more extensive capabilities.
Split-apply-combine: the concept
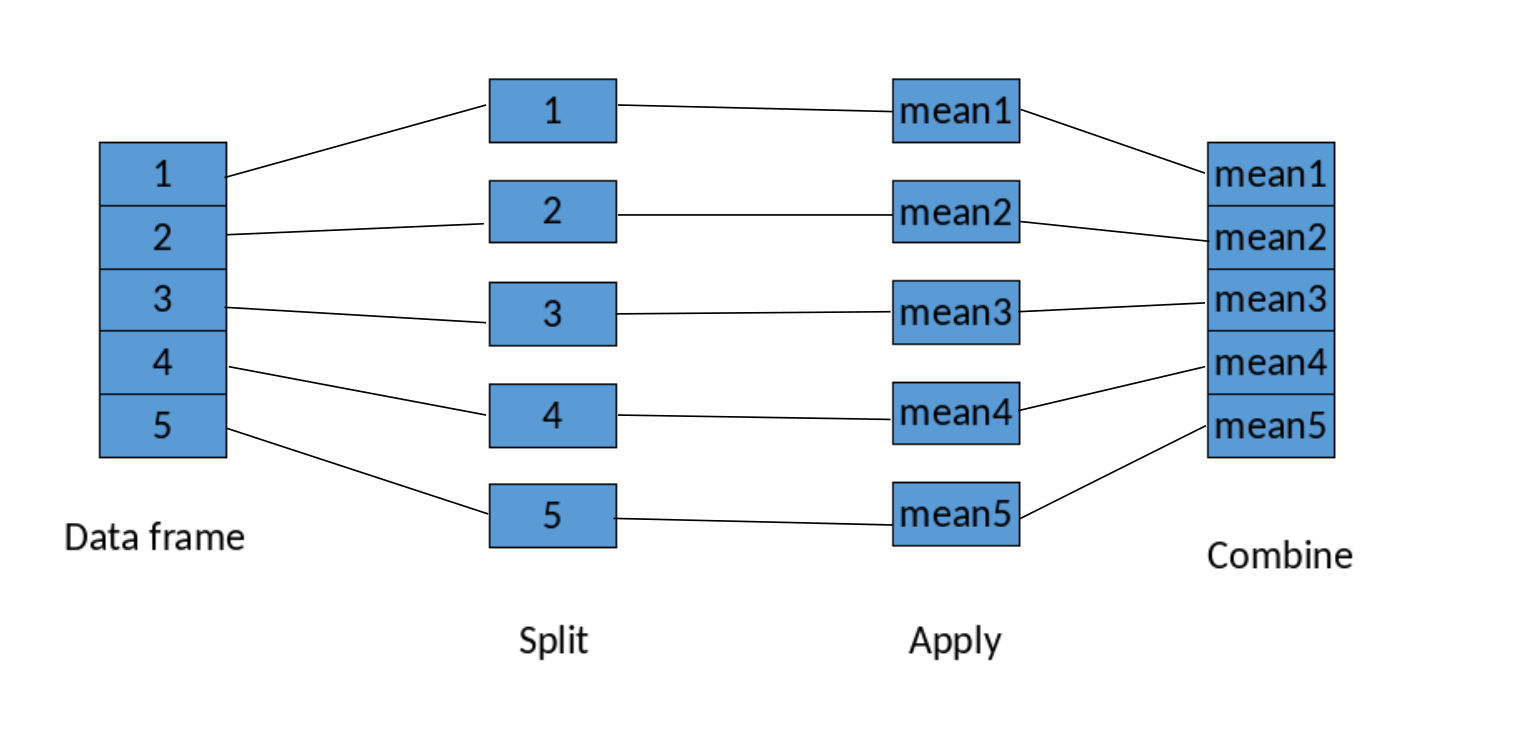
The idea is that we often have a data frame, with say 5 main groupings (fields, study plots, subjects, etc.). We want to split the data frame into these groups, and do something, i.e. apply. This can be as simple as just taking a mean to very complex analyses, or graphical summaries. Then, we want to combine it all back together in either a new data frame (summarize) or a new variable (transform). Below is a very simple graphical representation of this concept.
I know plyr so why change?
For those familiar with plyr, you are probably asking yourself, like I did, “I’m busy, I spent a lot of time learning plyr so why upgrade to dplyr?”. I’ll admit that I was initially reluctant and skeptical about some of improvements. Dplyr is promoted as being much, much faster than plyr but for me, this held little appeal. Up until recently, my data sets have been relatively small (low 10,000s or rows at the most). Waiting 0.2 seconds v. 2 seconds for a calculation is, quite frankly, not worth the time invested in learning something new. Another feature that held little appeal was the code is supposedly easier to read – big whoop I said to myself! I’m glad that I ignored these misgivings and kept reading.
The good stuff: why dplyr
There are two really great things about dplyr. First, while split-apply-combine was the essence of plyr, dplyr is essentially one stop shopping (along with tidyr – the new reshape2 – subject of another blog) for data wrangling. Basically, dplyr can do all of the following for a data set using 5 ‘verbs’ or functions:
– Filtering rows (to create a subset)
– Selecting columns of data (i.e., selecting variables)
– Adding new variables (split-apply-combine)
– Sorting
– Aggregating
The following website (http://www.sharpsightlabs.com/dplyr-intro-data-manipulation-with-r/) does a superb job introducing these concepts. I will simply suggest that you read it if you are interested in the detail. Obviously, all of these examples can be performed with other functions, particularly in base R. But now, it’s all unified in one package. Plus, there is a handy ‘cheat sheet’ (http://www.rstudio.com/wp-content/uploads/2015/02/data-wrangling-cheatsheet.pdf)
If that is not enough, the second really cool thing about dplyr is that it has borrowed the ‘piping’ concept in Unix, called ‘chaining’. Chaining is a really simple way to link your commands together and despite my earlier skepticism, it really does make reading code easier and that really does make a difference. I strongly encourage that you work your way to the last example on the above website. I concur with the author’s claim that 5 lines of code combining dplyr and ggplot2 would represent hours of work in MS Excel.
Having code that is easy to read makes life much easier, and lessens the dense of dread, when you come back to a project after months away from it.
Split-apply-combine: the code
The following is a simple example of split-apply-combine with plyr code and dplyr code. These take a dummy dataframe with a caribou per row and summarize it by the number of caribou by study area and year.
Dplyr code:
In order to run the following examples make sure you have dplyr, plyr, and tidyr installed and loaded:
install.packages("plyr")
install.packages("dplyr")
install.packages("tidyr")
library(plyr)
library(dplyr)
library(tidyr)You’ll also want to grab the csv from Chris’ google drive
In the following, the group_by command splits that data frame into Study Areas and Year. The data are summarised by count (apply) and then combined into a new data frame (pivot1). I cheated a little here and used a command from tidyr (next blog) just to make the output really nice.
mark <- read.csv("mark_data.csv") #Or whatever you downloaded it as
pivot1 <- mark %>% # calls the data frame
group_by(StudyArea, Year) %>% # splits groups intro study area and year
summarise(count = n()) %>% # counts the no. of caribou by study area and year
spread(Year, count) # converts the data to a ‘wide’ format StudyArea 2008 2009 2010 2011 2012 2013
1 30 40 24 25 25 NA
2 24 33 16 31 29 25
3 15 11 14 28 34 18
4 28 38 NA 24 24 NA
The following is plyr code equivalent to the above.
temp <- ddply(mark, .(StudyArea, Year), nrow)
pivot2 <- spread(temp, Year, V1) #V1 is the name of the column in temp for the count of rows, i.e. nrowAdmittedly, the plyr version is shorter in this simple example. I’ll make two points in favour of dplyr. First, the longer and more complex the code, the more useful chaining is (like in the webpage above). Secondly, and this could just be me, I never really got plyr syntax. It always seemed to do strange things. I just find dplyr is much more intuitive and the commands are more readily available thanks to the cheat sheet. There are additional benefits to dplyr as well, Chris shared my trepidation for trying dplyr, so he asked Hadley why he thought people needed to switch:
@CFHammill it's 10x-10,000x faster & and way easier to understand
— Hadley Wickham (@hadleywickham) June 11, 2015
In addition to speed and learning curve benefits, dplyr is a concerted effor to unify data manipulation under a common umbrella. Dplyr has facillities for connecting to external databases directly, so you don’t need to be a SQL master to pull useful information out of central repositories, and is expected to work well with SparkR, the emerging most popular tool in big-data.
Conclusion
Dplyr is a simple package that has functions for taking care of most of your data manipulation needs. We all spend a lot of time getting our data into the right format so that we can analyze it. Having ‘one stop shopping’ for this time consuming process that is fast and easy to read is a HUGE benefit.
Follow up
Wickham’s other really useful package is the reshape/tidyr package. Like his other popular packages, this one has also gone through an evolution from reshape, reshape2, and finally tidyr. For those of you who use pivot tables in Excel, this does similar things except for better. And while Excel can only go from long to wide (data in the model based format to tabular format), tidyr can take your data in both directions.